프론트엔드 면접에서 공통적으로 나왔던 질문이 있었다.
브라우저가 화면을 렌더링하는 원리에 대해서 설명하실 수 있어요?
검색을 해보면 프론트엔드 직무 지원자에게 가장 흔하게 물어보는 best 질문이라는 것을 알 수 있다.
물론 신입에게 세부적인 내용까지 알고 있으리라 기대해서 물어보는 건 아닐 테지만, 그래도 각각의 과정과 용어에 대해서는 어느 정도 말할 수 있어야 할 것 같다.(이제는 흔해 버린 질문이 되어 버린 만큼, '답변을 못한다. == 준비를 덜 했다.' 가 되어버린 것 같다..)
직무 면접을 준비하면서 이와 관련된 내용도 본 적이 있긴 했으나, 단순히 외워가는 정도로는 만족할 정도로 답변하기 어려웠다.
그래서 이참에 관련 내용을 정리해볼까 한다.
감사하게도 브라우저의 렌더링 동작에 대해서 네이버 D2에 어느 훌륭한 이스라엘 개발자(탈리 가르시엘)의 글을 번역해서 정리해놓은 글이 있다. 또한 다른 블로그에서도 많은 분들이 정리를 해주셔서 자료를 찾는 건 그리 어렵지 않았다.
이번 글에서는 브라우저의 렌더링 원리를 아주 깊게 이해하기 보다는 면접에서 자연스럽게 답변할 수 있는 수준을 목표로 작성되었다.
1. 웹 브라우저란?
흔히 Chrome, Safari, Firefox 모두 다 브라우저로 잘 알려져 있다.
그렇다면 브라우저가 정확히 무엇일까?
MDN문서에서는 다음과 같이 브라우저를 정의하고 있다.
웹 브라우저 또는 브라우저는 웹에서 페이지를 찾아서 보여주고, 사용자가 하이퍼링크 (en-US) 를 통해 다른 페이지로 이동할 수 있도록 하는 프로그램입니다. 브라우저는 가장 익숙한 타입의 사용자 에이전트 입니다. https://developer.mozilla.org/ko/docs/Glossary/Browser
컴퓨터 지식사이트 Computer Hope에서는 이렇게 설명해주고 있다.
Alternatively referred to as a web browser or Internet browser, a browser is a software program to present and explore content on the World Wide Web. These pieces of content, including pictures, videos, and web pages, are connected using hyperlinks and classified with URIs (Uniform Resource Identifiers).
즉 브라우저라는 것은 우리가 인터넷(web) 상에서 비디오나 사진, 웹 페이지들을 볼 수 있도록 도움을 주는 소프트웨어 프로그램이라는 것 같다.
다른 페이지의 문서를 찾아서 이동(하이퍼 링크)할 수 있고, 브라우저 주소창에 URI를 입력하면 웹 서버에 컨텐츠를 요청하여 받아볼 수 있다. 대부분 HTTP 통신 기반으로 HTML문서를 요청하긴 하지만, JPG, PNG와 같은 이미지들도 받을 수 있다. 서버에게서 받은 컨텐츠의 종류는 일반적으로 HTTP 응답 헤더 중 Content-type에 MIME type으로 표시되어 있다.
URI vs URL?
URI
- Uniform Resource Identifier
- 인터넷 상에서 자원을 식별하는 문자열
URL
- Uniform Resource Locator
- 인터넷 상에서 자원의 위치를 나타내는 문자열
- URI에 포함되는 하위 개념
어떤 블로그에서는 URL 주소가 scheme부터 path까지만이라고 설명하는데, 정확한 의미는 아닌 것 같다. query 스트링도 url의 구성 요소가 될 수 있기 때문이다.
다만 #로 이어지는 fragment는 자원의 위치가 아닌 자원의 특정 부분을 가리키는 문자열이므로 fragment 까지는 URL이 될 수 없다.
query 스트링은 path에 있는 데이터에 관한 세부적인 요구사항을 의미하긴 하지만, 그 자체가 자원을 의미하는 것은 아니다. 예를 들어, ?title=a&info=something 이라고 하는 query 스트링의 경우에는 path에 있는 자원 중 title이 a이고 info가 something인 곳의 리소스를 요청한다는 의미이지, title=a&info=something이라는 파일 자체를 요청한다는 의미가 아니다.
누군가 서울시 성동구 xx아파트 a동 501호 문 앞에서 거실 옆 방에 있는 사람을 불렀다고 해보자. 만일 그 방에 H밖에 없다면 이 정보만으로도 특정되겠지만, H의 형도 같은 방에 있다면 H와 형은 서로 누구를 부르는지 알 수 없을 것이다.
이 상황에서 두 사람을 식별하려면 그냥 이름을 불러야 정확하게 H를 부를 수 있다. 이 예시에서 URL은 집 주소와 방의 위치까지를 의미하고, 이름까지 이어지면 곧 URI가 된다. 물론 집 주소도 H를 식별하는 정보 중 일부이므로 URI가 될 수 있다.
MIME TYPE이란?
https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/MIME_types
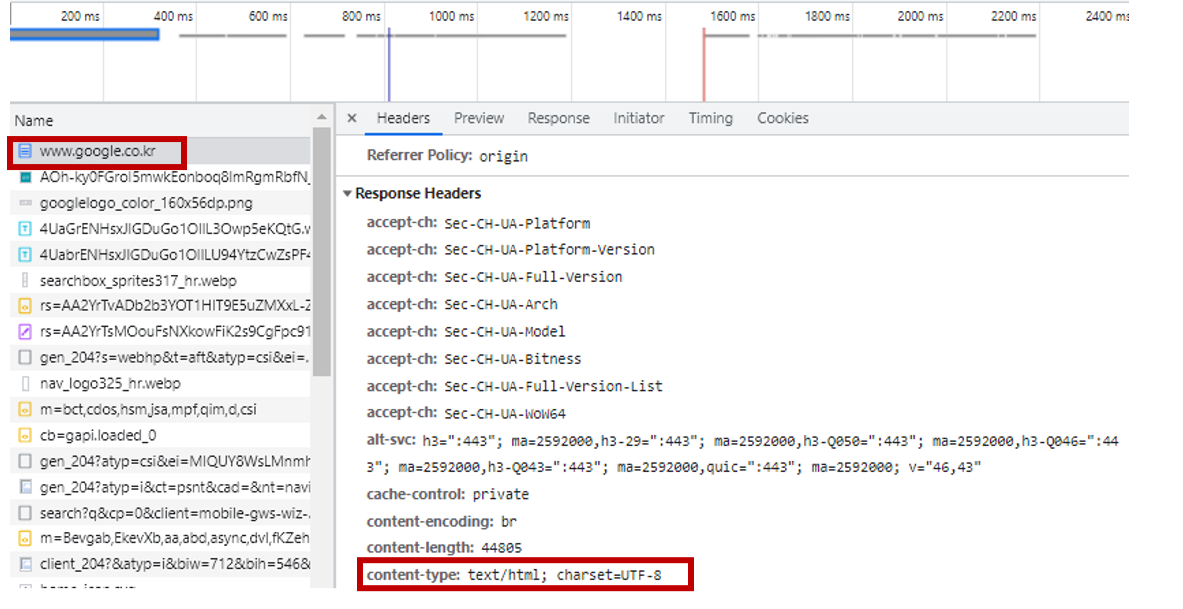
마임 타입이라고 읽는다. 브라우저가 http 프로토콜로 요청하겠습니다. ??? 위치에 있는 xxx를 주세요!라고 서버에 요청하면, 서버는 요청에 응답할 때 그 xxx가 HTML 문서인지, jpg 이미지인지, 혹은 다른 무엇인지 표기해준다. 이러한 표기법을 MIME type이라고 부른다.
만약 서버에게서 HTML 문서를 받았다면 브라우저가 응답 받은 컨텐츠의 타입이 text/html 라고 적혀 있을 것.
브라우저에서 제공하는 여러 인터페이스를 통해 우리들은 단순히 마우스 클릭이나 키보드 입력만으로 다음 두 가지 작업을 편리하게 수행할 수 있다.
- 웹 서버와 통신
- 통신 결과로 얻은 데이터를 화면에 표시
만약 브라우저가 없었다면 어땠을까?
아마 우리들은 **네트워크 통신을 위한 여러 작업(서버의 IP 주소를 알아내는 작업, 3-way handshaking 등)**을 하고 안녕하세요.지금 URI에 있는 컨텐츠를 HTTP 양식에 맞게 저희 쪽으로 응답 바랍니다.와 같은 요청 헤더를 매번 작성해야 하지 않았을까?
게다가 서버에게서 받은 응답 내용을 하나씩 다 풀어 헤쳐야 했을 것이다. 그 내용을 우리가 보기 좋게 다듬는 것(렌더링) 역시 별도의 작업이다. 상상만 해도 끔찍하다.
그렇다면 브라우저는 어떻게 웹페이지를 보여주는 것일까?
대부분의 웹페이지가 HTML 컨텐츠로 브라우저에 전달되므로, HTML 문서를 받았다고 가정한다.
2편은 브라우저 렌더링 동작에 관한 글로 이어진다.